Phonometrica¶
Overview¶
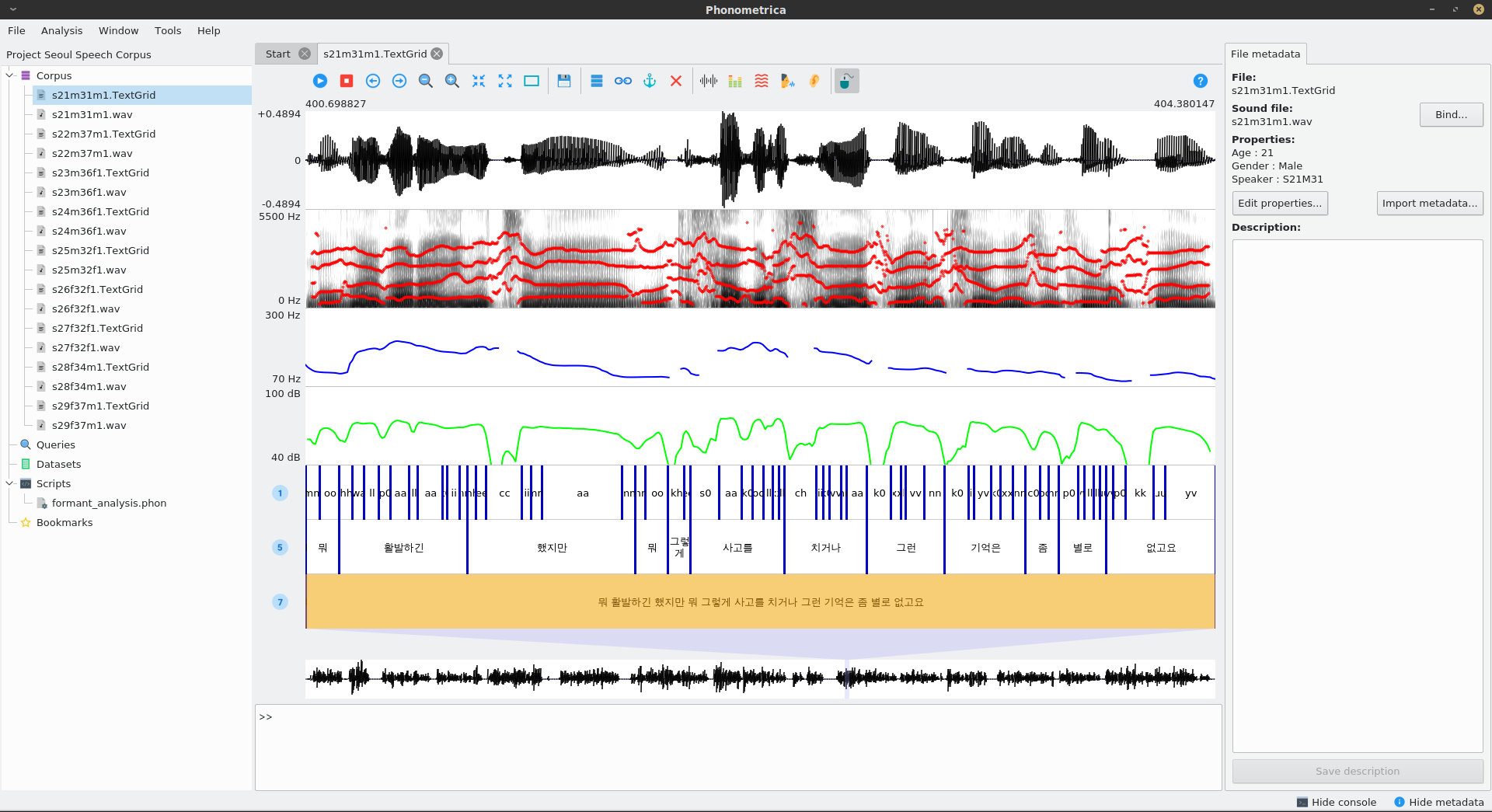
Phonometrica is a free, open-source software platform for the annotation and analysis of speech corpora. It offers a user-friendly interface to manage, annotate, analyze and query language corpora. It is particularly well suited for dealing with time-aligned data. The main features it offers are:
Project management: organize files into projects.
Sound visualization and annotation: visualize and annotate speech sounds on multiple layers
Extensible metadata: annotate files with properties, which allow you to sort and organize your corpus.
Queries: build and save simple or complex queries; search strings or patterns across layers.
Data analysis: hypothesis testing, linear, logistic and Poisson regression
Scripting engine: Phonometrica can be configured and extended with an easy-to-use scripting language and JSON files.
Standard-based: Phonometrica files are encoded in XML and Unicode.
Interaction with Praat: Phonometrica can read and write TextGrid files and open files directly in Praat.
Phonometrica runs on all major platforms (Windows, macOS and GNU/Linux) and is freely available under the terms of the GNU General Public License. The latest version can be downloaded from http://www.phonometrica-ling.org. If you have questions, problems, or would like to report a bug, please contact us at phonometrica.dev@gmail.com.
Download¶
Phonometrica 0.7.6¶
Windows 7 and later: setup_phonometrica.exe
MacOS 10.12 and later: phonometrica-0.7.6.dmg
Linux (Debian 10/Ubuntu 20.04): phonometrica-0.7.6.deb
source code: phonometrica-0.7.6.zip | phonometrica-0.7.6.tar.gz
Topics¶
How to cite?¶
To cite Phonometrica, you can use the following citation [EYC2019]:
- EYC2019
Eychenne, Julien & Léa Courdès-Murphy (2019). Phonometrica: an open platform for the analysis of speech corpora. Proceedings of the Seoul International Conference on Speech Sciences 2019, Seoul National University, pp. 107-108.